Generating Text Classification Training Data With Zero-Shot Transformer Models

Zero-shot text classification is truly a transformative piece of technology. These models can classify text into arbitrary categories without any fine-tuning [1]. This technology provides two main benefits over traditional supervised text classification learning approaches. First, they make it possible to perform text classification when labelled data is non-existent, as no fine-tuning is required. Next, a single model can be used to classify thousands of different labels.
However, zero-shot text classification models are often large. For example, one of the most popular zero-shot text classification models is based on the BART-large transformer architecture which has over 400 M parameters. This article will discuss how to use a zero-shot text classification model to produce training data and then use the generated training data to then train a smaller model that still performs well. As a result, this will allow NLP practitioners to train smaller models that can be more easily implemented in production by reducing hardware requirements and energy consumption.
Related Works
Self-labeled techniques for semi-supervised learning: taxonomy, software and empirical study:
Discusses various self-labelling techniques. The basic concept is to use a labelled dataset to help label an unlabelled dataset so that you have more training cases. [2]
Zero-shot Text Classification via Reinforced Self-training:
Discusses using reinforcement learning and BERT to determine training cases, which are then used to train a BERT model. [3]
Processes
Let's discuss the overall process for this system. First off, unlabelled data is required. For these experiments, I used a dataset called the Stanford Sentiment Treebank V2 (SST2), which is available through Hugging Face's Dataset distribution network. This dataset contains the text for movie reviews along with 1 of 2 potential labels to indicate if the review is "positive" or "negative." However, we do not need to use the labels for the sake of this training process.
Zero-shot models require two inputs: a list of labels and text. In this case, we'll provide the labels "positive" and "negative" along with the movie reviews text. Then, for each case, the model will output a score for both of the labels. Since we know that the review must belong to only one of the two potential labels, we select the label with the highest score.
At this point, we have a dataset that contains labels produced by the zero-shot classifier. It's important to note that not all of the labels will be correct as the zero-shot text classification model does not have 100% accuracy. But, we can still use this dataset to train a supervised learning model. So, we'll train a simple Naive Bayes classifier with a package called TextBlob.
Finally, the model can be evaluated using the original datasets already labelled evaluation data. In the absence of labelled evaluating data, I suppose you can follow a similar process of using the zero-shot text classification model to production evaluation labels. However, this method would not give you a definitive accuracy for your model.

Experiments
Zero-shot Models
First off, let's discuss the accuracy of zero-shot text classification models. The top two most downloaded zero-shot text classification models on Hugging Face's model distribution network were used for the experiment: "typeform/distilbert-base-uncased-mnli" and "facebook/bart-large-mnli." They were evaluated on the entire "validation" set of the SST2 dataset, which contained 872 cases. As expected, the BART model performed better with an accuracy of 0.8819 while the DistilBERT model's accuracy was 0.7592.
| Model | Accuracy |
|---|---|
| typeform/distilbert-base-uncased-mnli | 0.7592 |
| facebook/bart-large-mnli | 0.8819 |
Training a Supervised Model With Zero-shot
A Naive Bayes classier was trained using TextBlob due to its simplicity and size. This model uses "traditional" NLP classification techniques, which require significantly less resources than deep learning approaches, like Transformers.
Below is a chart that shows the results. Just as a reminder, the model that produced the training set achieved an 0.8819 accuracy, and a smaller zero-shot model achieved a 0.7592 accuracy. The Naive Bayes classifier consistently improved as the number of training cases increased and had a final accuracy of 0.7603.
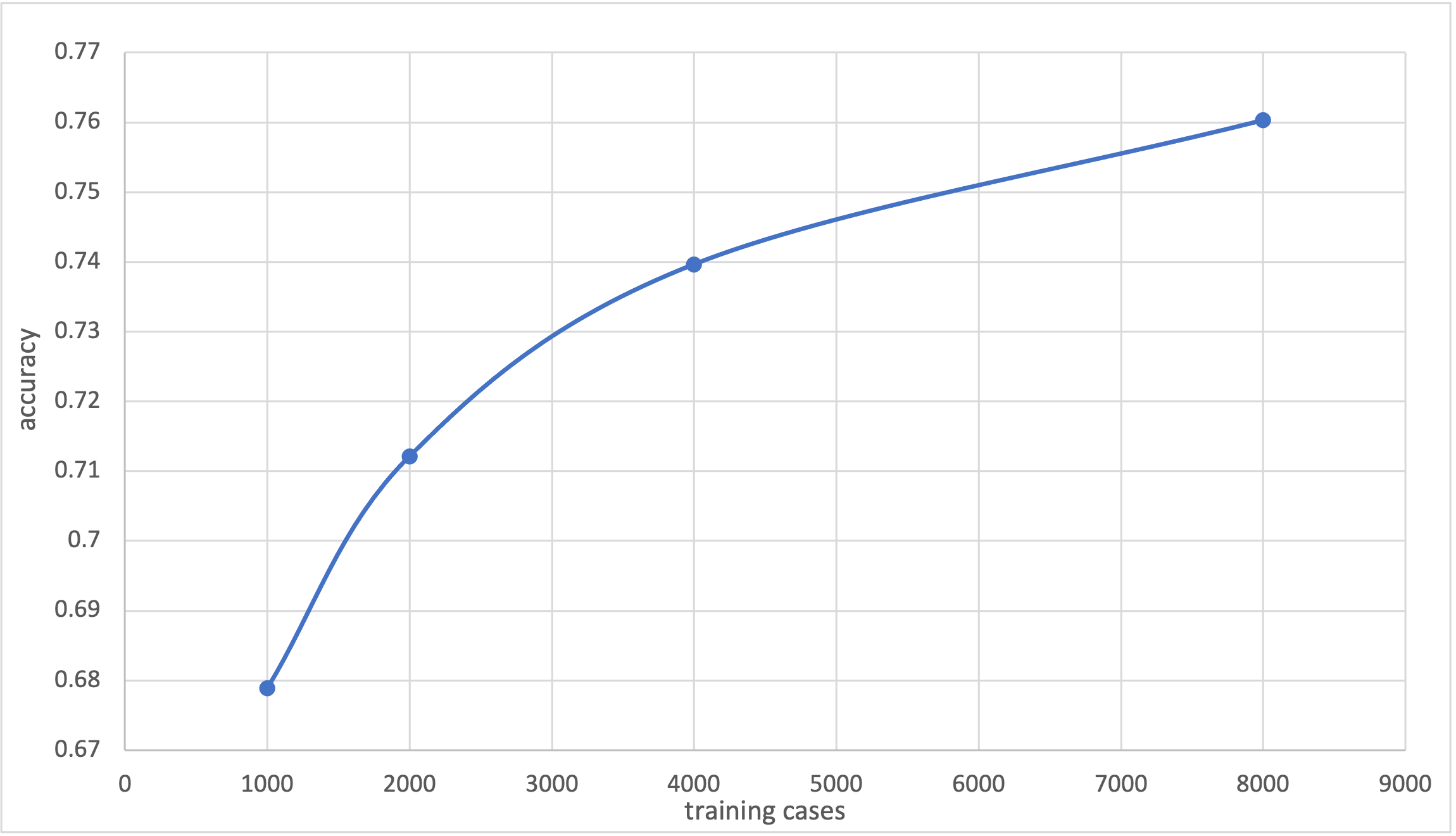
Fully Supervised Model
The zero-shot data generation method inevitably results in some of the cases being mislabelled. So, I assume that this would negatively affect performance compared to if the data was fully labelled correctly. To measure the negative effect, I conducted the same experiment as described above, except I used the actual labels over the generated labels. To my surprise, the model only performed slightly better. Below is a table that gives a clear comparison.
| Cases | Generated Labels | Actual Labels |
|---|---|---|
| 1000 | 0.6789 | 0.6778 |
| 2000 | 0.7122 | 0.7236 |
| 4000 | 0.7397 | 0.7569 |
| 8000 | 0.7603 | 0.7695 |
Future Work
More powerful supervised models:
For this article, we covered how to train Naive Bayes using the generated training data. However, other text classification models, would likely perform better while still being significantly smaller than the initial zero-shot model. I conducted an experiment using 1000 generated training cases to train distil-bert-base-uncased with Happy Transformer. This model achieved an accuracy of 0.7856 using the default settings. However, as I increased the number of training examples, the model did not substantially improve, which is likely a sign of overfitting. In the future, I plan on performing additional experiments to find better hyperparameter configurations.
Thresholding:
Applying thresholding can potentially improve performance and allow for data to be collected more easily. A conditional statement can be added that would reject cases with a low certainty. So, this may improve performance as fewer cases that are labelled incorrectly would be used for fine-tuning. Additionally, this could be used to parse through a large amount of data where the majority of the data is unrelated for the target labels.
Iterations:
Labelling data may be done in iterations, where after each iteration the supervised model is used to label unseen cased with the zero-shot model. So, let's say the starting accuracy of the zero-shot model is 90%. Then, after labelling 1000 training cases and training the supervised model, its accuracy may be 80% accuracy. These two models can be combined to label an additional 1000 training cases, and the process can continue as the supervised model's accuracy increases. Eventually, the zero-shot model may no longer be needed to label the cases, which would greatly improve efficiency.
Outlook
I envision a future in which the need for manually labelling data is greatly diminished. As time progresses, it's reasonable to assume that both the size and quality of zero-shot text classification models will increase. Although I have just scratched the surface of applying this technique, I have shown that this technique can result in models with good performance that require a fraction of the computational requirements of the initial zero-shot model.
References:
[1]https://arxiv.org/abs/1909.00161
[2]https://link.springer.com/article/10.1007/s10115-013-0706-y
[3] https://www.aclweb.org/anthology/2020.acl-main.272.pdf
Code
 Vennify-Inc
Vennify-IncPlease contact me if you have experience in NLP research and believe that this experiment is or is not original enough to lead to a published paper.




