Keyword Extraction With KeyBERT

KeyBERT is an open-source Python package that makes it easy to perform keyword extraction.So, given a body of text, we can find keywords and phrases that are relevant to the body of text with just three lines of code. KeyBERT has over 1.5k stars and was created by the author of BERTopic which has 2.5k stars. And thus, you can be assured that the package is well respected within the NLP community.
Methodology
Before we discuss how to use the KeyBERT, it's useful to we gain a basic understanding of how the package works. This would allow us to better understand what the outputs mean along with the package's limitations and abilities.
There are four steps that KeyBERT accomplished to produce predictions. These steps are based on this article by the author that provides more in-depth explanations. From a high level, the package computes a vector that represents the meaning for each possible word/phrase and a vector for the meaning of the overall document to then determine the words/phrases that are the most similar to the overall document using the computed vectors.
Step 1: Word/phrase extraction
The first step is to determine possible words and phrases. The author used scikit-learn's CountVectorizer to determine the possible words/phrases. CountVectorizer tokenizes a text input and allows the programer to specify the range of n-grams we would like to consider. It counts the number of occurrences of each n-gram range. But, KeyBERT does not consider the number of occurrences of each n-gram range and instead only considers the n-grams that have occurred regardless of their frequency.
Example:
In the example below we show the input sentence "The King and the Queen met to discuss the King's party." Stop words are removed and it is converted into the uncapitalized form which results in the text "king queen met discuss king party". From here, we can extract unigrams and bigrams.
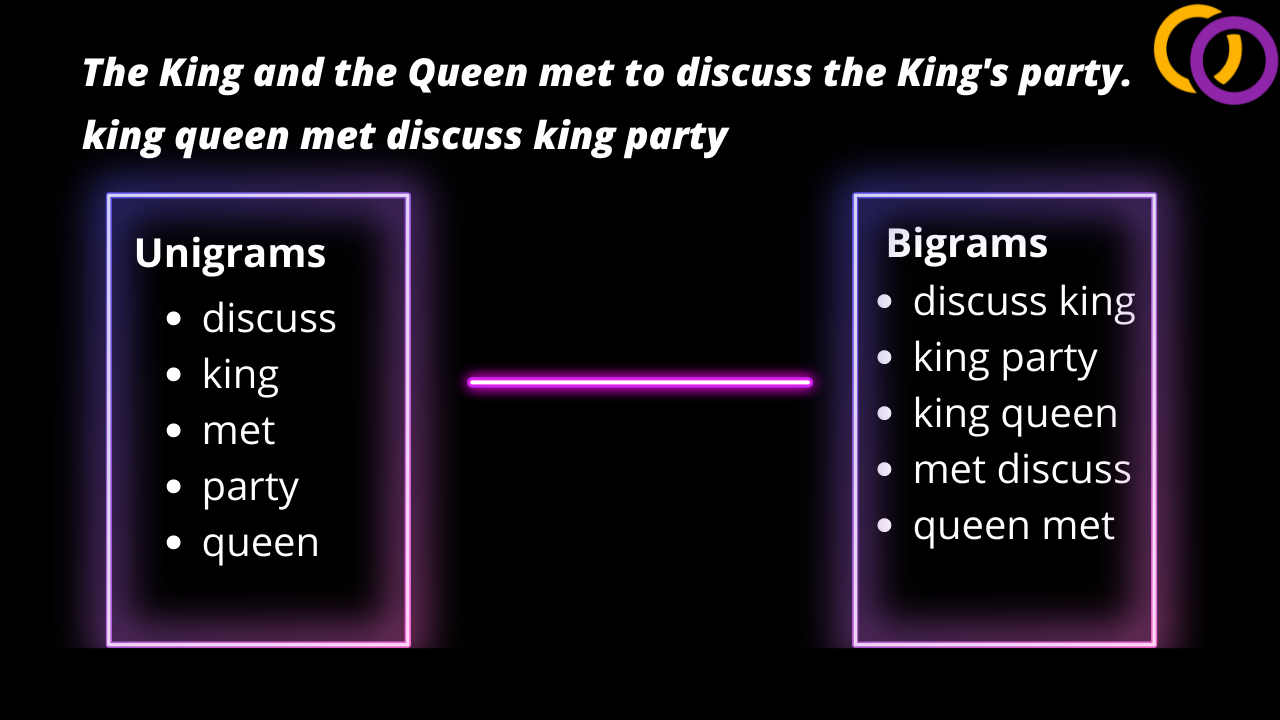
Step 2: Vectors
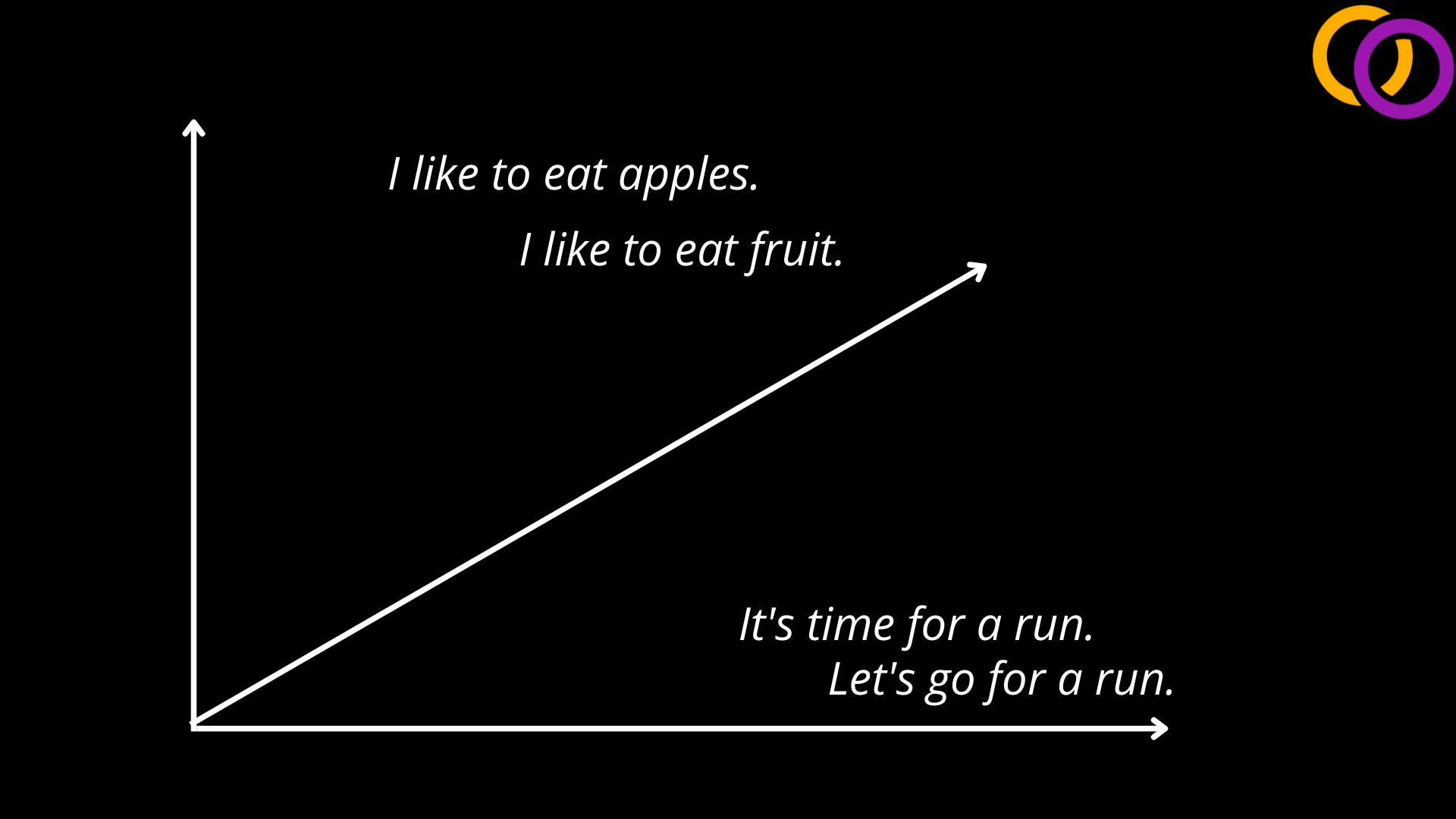
The next step is to use a package called Sentence Transformers library to compute vectors that represent the meaning of both the extracted words/phrases and the overall document. I've recently published a full article on Sentence Transformers which I recommend you check out to learn more. But, to explain briefly, you may have heard of tools like Word2vec which are able to compute vectors that represent the meaning of single entities, as shown in Figure 2. Now, the authors of Sentence Transformers found a way to efficiency compute vectors to represent the meaning of entire documents. Figure 3 shows an example of vectors being mapped in three dimensional space for short sentences. Notice how sentences that are similar are close together.

Step 3: Comparing Vectors
The author of KeyBERT then compared the vectors produced for the words/phrases to the vector produced for the entire document. He used the cosine similarity between the vectors as the metric to determine the distance between them. So, the vectors for the keys that were close to the vector for the document were selected as the top keys.
Step 4: Diversification
The author applied techniques to diversify the keys that were chosen. Without applying these techniques, the model may select very similar words/phrases as the top keys. For example, if had an article on fruit that included many different fruit species and did not apply this technique the top three keys may be "green apple," "big apple," "yellow apple." We may instead want the program to include a variety of different fruit species within the top keys even if one was more prevalent within the article.
In this tutorial, I will not explain the techniques behind how diversification is applied. If you are interested to learn more, I recommend you read the article by the author of KeyBERT that further explains this topic.
Code
Install
Let's start by installing keybert from PyPI.
pip install keybertImport
Let's import a class called KeyBERT to load the model.
from keybert import KeyBERT
Model
Let's not create an object using our KeyBERT class. By default a model called all-MiniLM-L6-v2 is used. But, it is possible to use other models from this webpage. To use an alternative model, pass the model name to the first positional parameter. The author recommends using a model called paraphrase-multilingual-MiniLM-L12-v2 for multi-lingual text.
kw_model = KeyBERT()
kw_model_multi = KeyBERT('paraphrase-multilingual-MiniLM-L12-v2')
Data
We'll use text from one of my articles called "Generating Text Classification Training Data With Zero-Shot Transformer Models."In this article I used a zero-shot text classification Transformer models to label training data so that a supervised model could be trained. So, we should expect that the keywords includes words like "text classification" and "training data."
doc = """
Zero-shot text classification is truly a transformative piece of technology.
These models can classify text into arbitrary categories without any fine-tuning [1].
This technology provides two main benefits over traditional supervised text classification learning approaches.
First, they make it possible to perform text classification when labelled data is non-existent, as no fine-tuning is required.
Next, a single model can be used to classify thousands of different labels.
However, zero-shot text classification models are often large.
For example, one of the most popular zero-shot text classification models is based on the BART-large transformer architecture which has over 400 M parameters.
This article will discuss how to use a zero-shot text classification model to produce training data and then use the generated training data to then train a smaller model that still performs well.
As a result, this will allow NLP practitioners to train smaller models that can be more easily implemented in production by reducing hardware requirements and energy consumption.
"""Keyword Extraction
Now, we just need to call our KeyBERT object's extract_keywords() method to output the results. We'll provide the document to the first positional parameter and then provide the number of keys we would like to receive to the "top_n" parameter.
The output is a list of tuples where the first index in the tuple is the string value for the key and the second value is the for distance of the key which can be thought of as a score to reflect the model's certainly between the range of 0 to 1 with higher values being more certain.
keywords = kw_model.extract_keywords(doc, top_n=10)
print(keywords)Output:
[('text', 0.3842), ('classification', 0.3567), ('nlp', 0.3539), ('supervised', 0.3105), ('learning', 0.3065), ('classify', 0.2866), ('shot', 0.2855), ('models', 0.2615), ('labels', 0.2446), ('categories', 0.2385)]
We see that the model was indeed able to identify words that appear to reflect the meaning of the text.
Keyword Highlighting
We can call our KeyBERT's extract_keywords() while setting the highlight parameter to True to print an output to shows the result.
keywords = kw_model.extract_keywords(doc, highlight=True)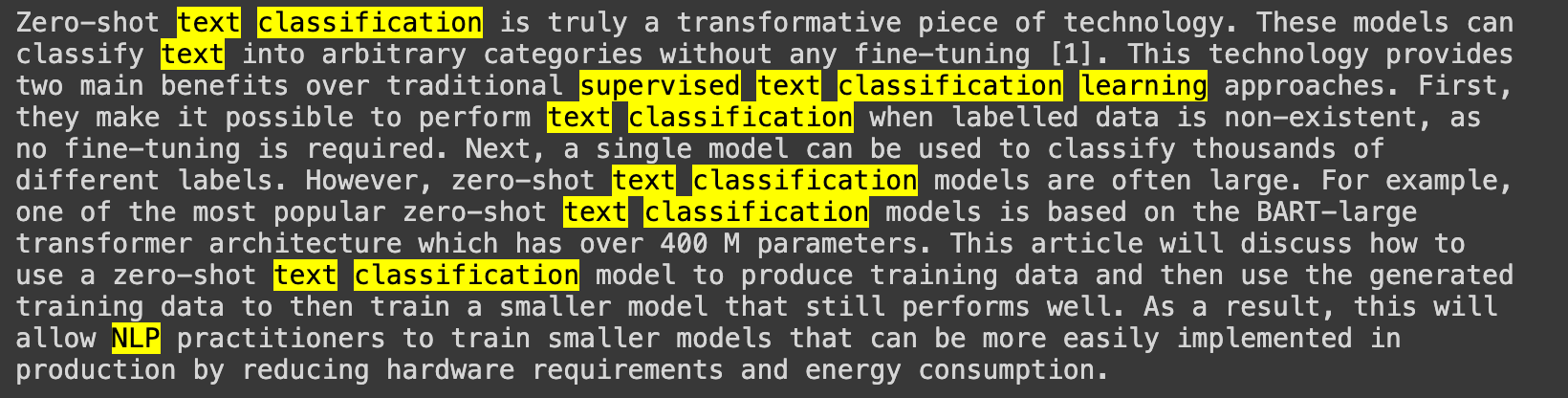
Settings
Phrases
In the previous example, we just considered single tokens/words as potential keys. We can adjust this to consider a range of tokens as possible keys. This is accomplished by providing a tuple to the keyphrase_ngram_range parameter.
keywords = kw_model.extract_keywords(doc, keyphrase_ngram_range=(2, 2), top_n=10)
print(keywords)Output:
[('shot text', 0.5327), ('classify text', 0.5255), ('text classification', 0.5198), ('supervised text', 0.5055), ('zero shot', 0.4965), ('classification models', 0.3962), ('training data', 0.367), ('labels zero', 0.366), ('classification model', 0.3593), ('classification learning', 0.353)]
Max Sum Similarity
We may want the model to produce a more diverse set of keys. In the example above, the output contained the word "classification" four times along with the word classify within the top ten keys. We use an algorithm called max sum similarity to diversify the output by seeing the use_maxsum parameter to true and providing an integer to nr_candidates.
keywords = kw_model.extract_keywords(doc, keyphrase_ngram_range=(2, 2), use_maxsum=True, top_n=10, nr_candidates=20)
print(keywords)[('popular zero', 0.3028), ('generated training', 0.3075), ('learning approaches', 0.3217), ('allow nlp', 0.3218), ('nlp practitioners', 0.3245), ('classification truly', 0.345), ('models classify', 0.3507), ('perform text', 0.3522), ('labels zero', 0.366), ('zero shot', 0.4965)]
Conclusion
And that's it! From here I recommend you check out my previous article that covers topic modelling with BERTopic – a package that allows you to determine what topics are part of text. As I've mentioned before, it was created by the author of KeyBERT. Be sure to subscribe to my YouTube channel as I'll be uploading a video on KeyBERT in the future.
Here's the a Google Colab notebook that contains the code from this tutorial.




