Llama-2 Made Easy. Fine-tune and Perform Inference With a Transformer Model

YouTube version of the article:
Fine-tuning models like Llama-2 and GPT-J is now easier than ever with Happy Transformer. Happy Transformer is a Python package my team created that abstracts many of the complexities typically involved with fine-tuning Transformer models. We just released version 3 of the library that supports Microsoft's DeepSpeed which allows you to quickly leverage 8 GPUs at once to fine-tune Llama-2 and other models. So, it's now possible for a complete NLP beginner to fine-tune Llama-2 in a matter of minutes.
TLDR:
# Rent an 8xGPU instance with each GPU having 48GB+ of VRAM
# DS_BUILD_UTILS=1 pip install deepspeed
# pip install happytransformer
# call this script with the command "deepspeed train.py"
from happytransformer import HappyGeneration, GENTrainArgs
happy_gen = HappyGeneration(model_type="LLAMA-2", model_name="meta-llama/Llama-2-7b-chat-hf")
args = GENTrainArgs(deepspeed='ZERO-2")
# Seperate your total data into two text files: "train.txt" and "eval.txt"
happy_gen.train("train.txt", args=args, eval_filepath="eval.txt")
happy_gen.save("llama/")
Part 1: Rent an Instance
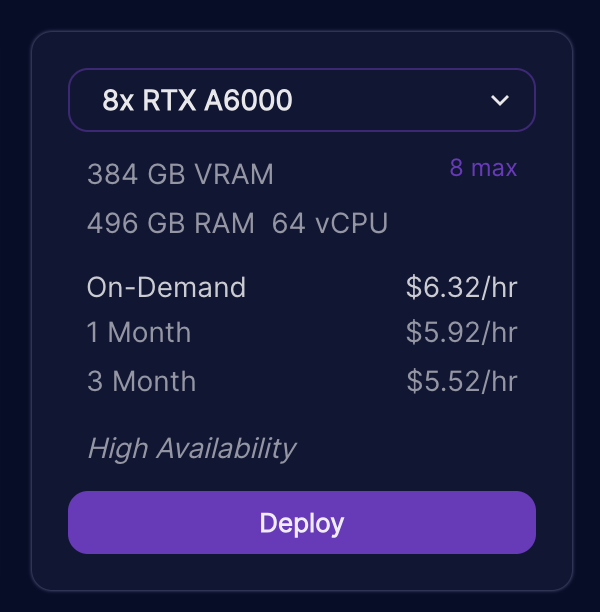
We recommend renting 8 NVIDIA GPUs each with at least 48GB of VRAM each. Runpod.io has good availability for instances that meet this specification for as low as $6.32 USD/hr.
Here are the steps to create a RunPod.io instance to train Llama-2:
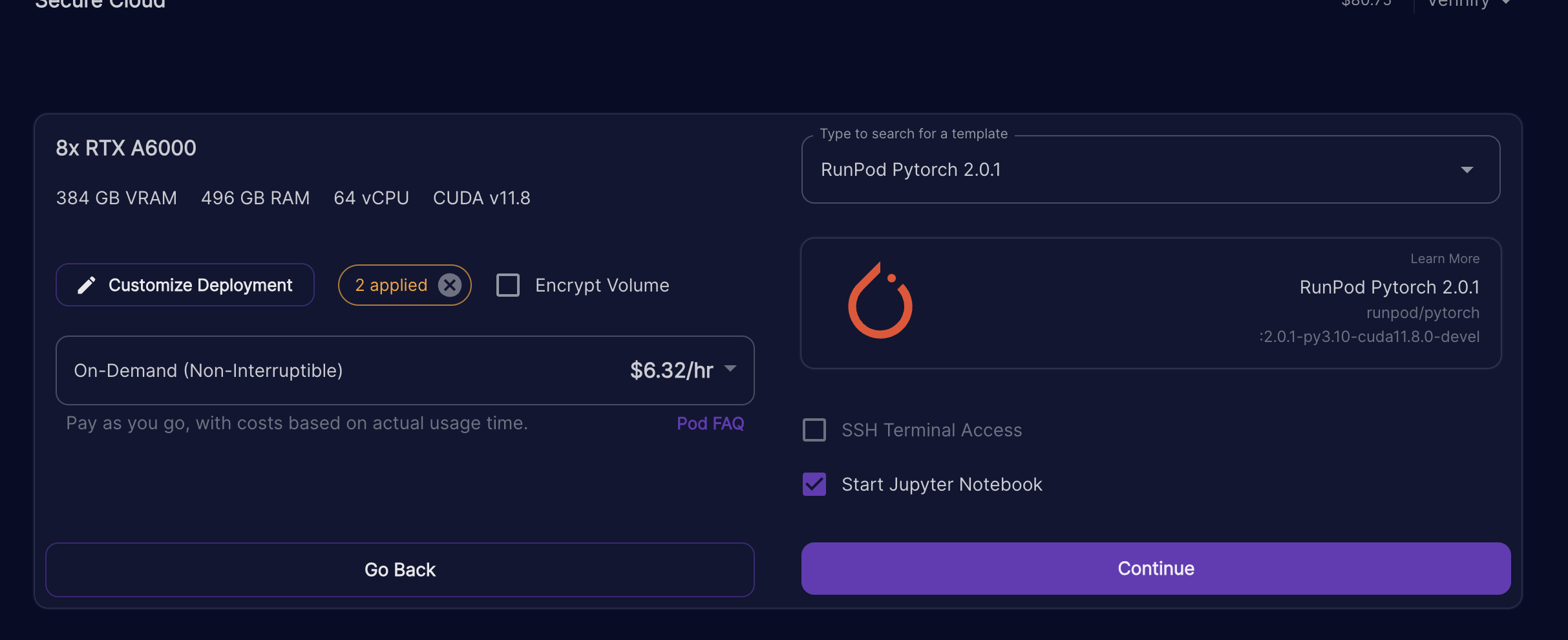
4. Select deploy for an 8xRTX A6000 instance. Other instances like 8xA100 with the same amount of VRAM or more should work too.
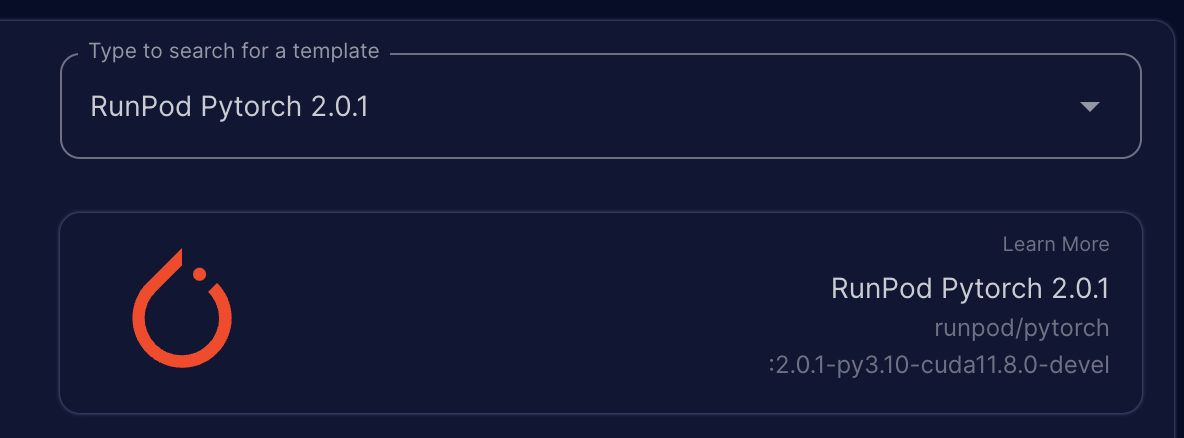
5. Change the template to RunPod PyTorch 2.0.1
6. Click customize deployment and change container disk to 400gb and volume disk to 400gb. Then select set overrides.
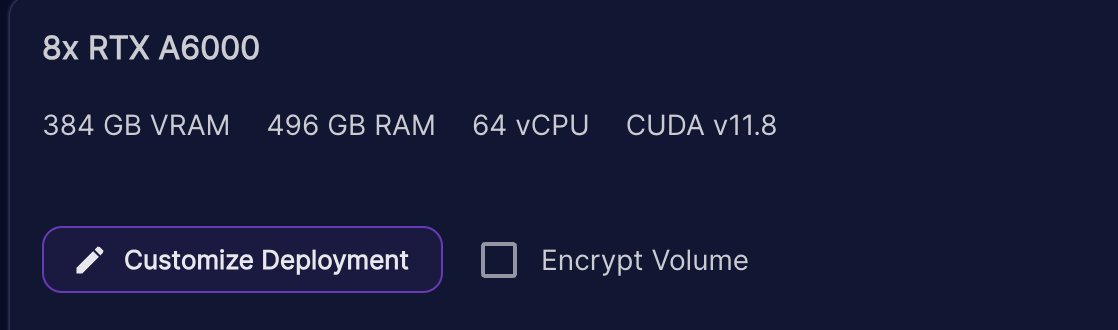
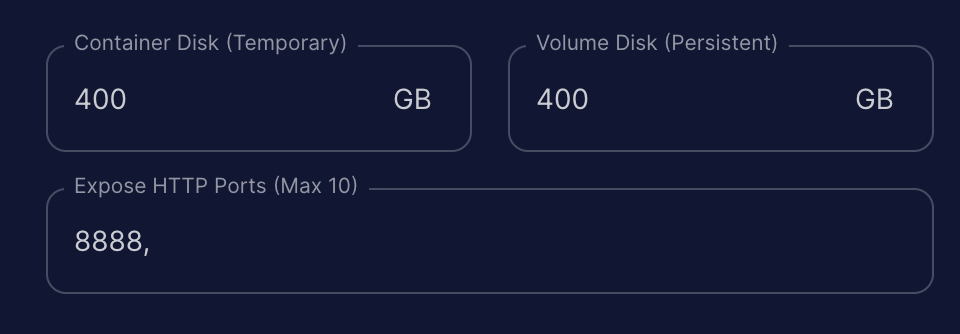
7. Your final configuration should look something like the photo below. Be sure to select "Start Jupyter Notebook" as well.
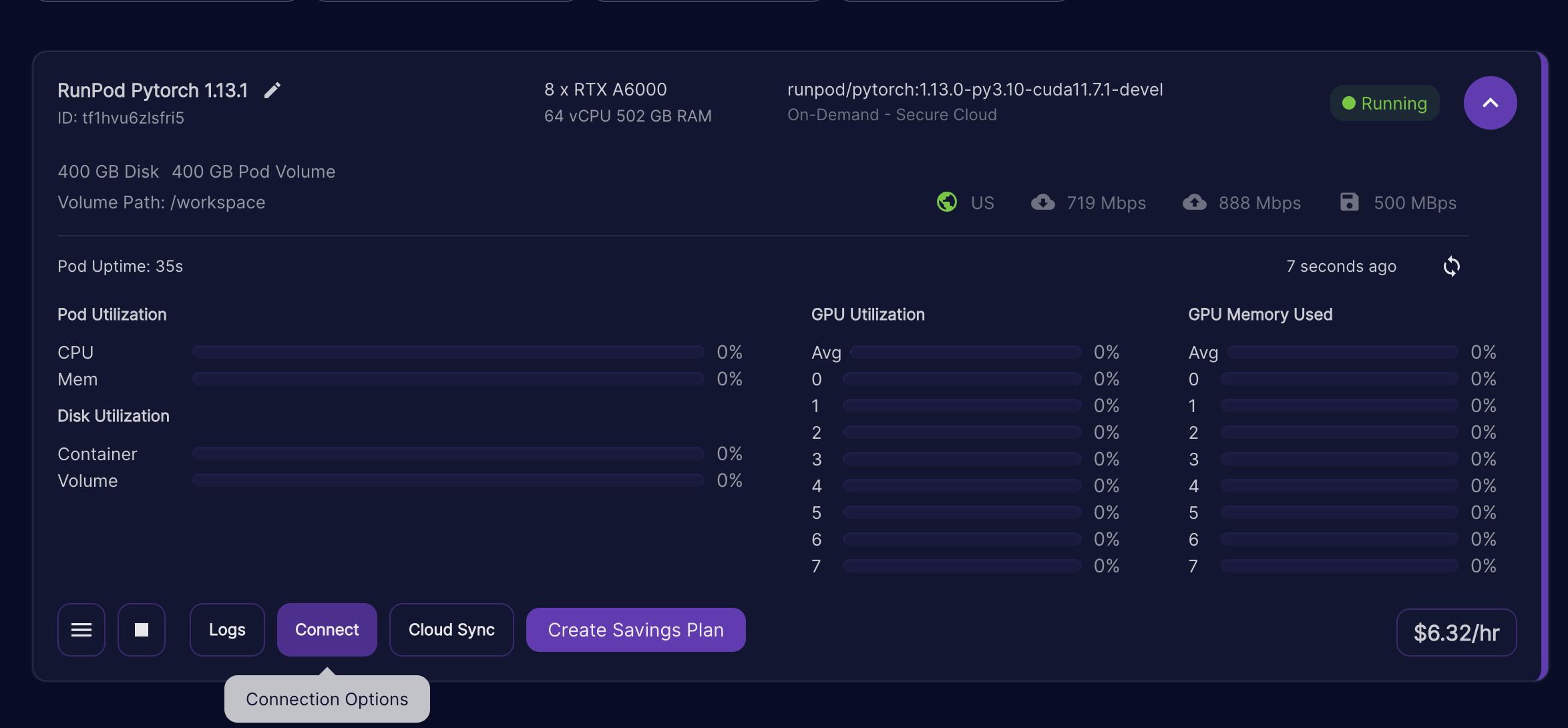
8. Go to your pods and select Connect for the instance you just created.
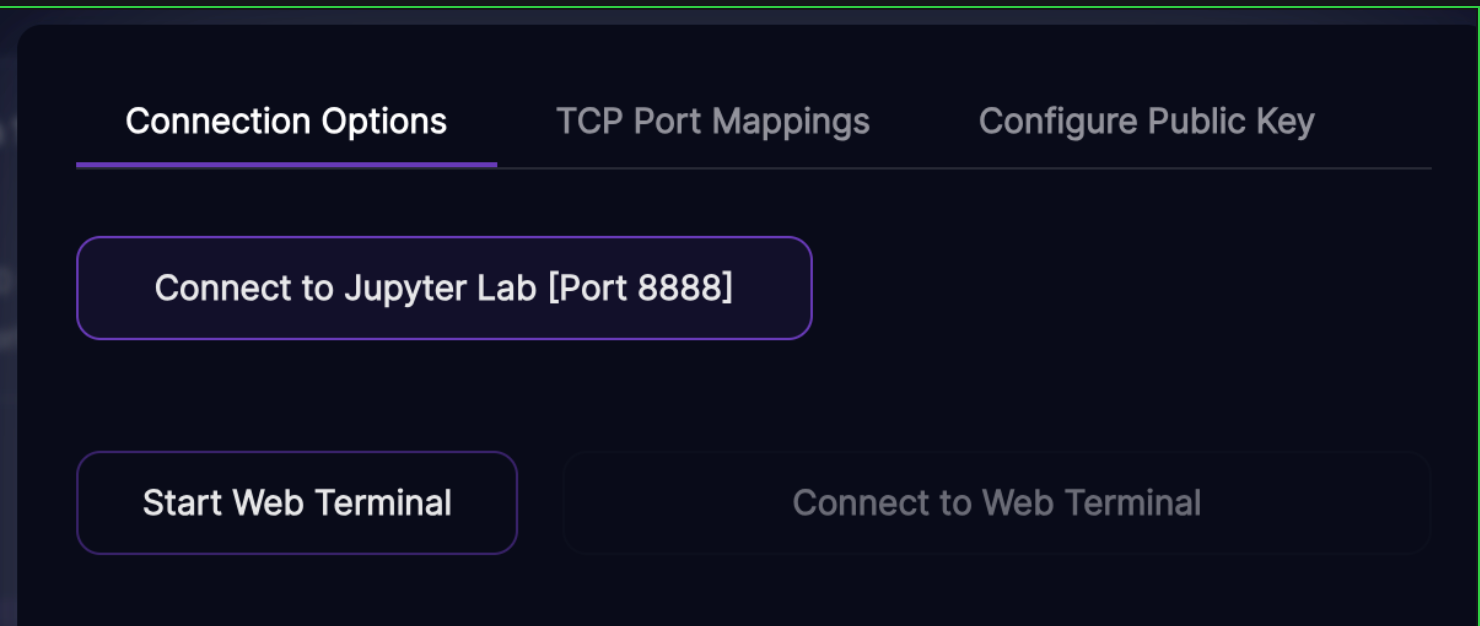
9. Select "Connect to Jupiter Lab [PORT 8888]"
10. We're now within a Jupiter Notebook environment which I'm sure is quite familiar to you. Open a terminal and proceeded to the installation instructions.
Part 2: Installation
DeepSpeed
Run the following command within your terminal to install DeepSpeed.
DS_BUILD_UTILS=1 pip install deepspeedHappy Transformer
Happy Transformer can be installed from PyPI with the command below. We are using version 3.0.0 for this tutorial
pip install happytransformerPart 3: Request Llama-2
To gain access to Llama-2 you must first request access by completing this form and then wait to be approved. Use the same email as your Hugging Face account for your request.
As you're waiting, I suggest you fine-tune GPT-J which is a 6 billion parameter model created by EleutherAI as the steps to train this model are identical as the steps to train Llama-2
To use Llama-2, you'll need to download the model from Hugging Face's Model Hub. First login to Hugging Face using their command line tool. If you would like to fine-tune GPT-J instead of Llama-2, then you can skip this step as logging in is not required to download GPT-J.
huggingface-cli login Select "yes" for git credentials if you would like to push the final model to the Hub.
Part 4: Training Script
We'll base this tutorial on the official text generation example for Happy Transformer. We'll fine-tune a model on summarizations of US Congressional and California bills. So, the model will learn to produce text that sounds like legalese and mentions common themes you expect to find in American bills.
We just need to produce a text file or a CSV file (with a single column called text) to fine-tune a model with Happy Transformer. The text can be from any domain and after you've converted your data into one of these two formats it's just a few lines of code to fine-tune a model. The script below shows the entire process of fetching data form Hugging Face Hub, preprocessing it into a text file, and then installing the Happy Transformer components and running training.
Script
Comment out the happy_gen line and uncoment the line below it to use Llama-2 instead of GPT-J.
from datasets import load_dataset
from happytransformer import HappyGeneration, GENTrainArgs
def main():
train_txt_path = "train.txt"
eval_txt_path = "eval.txt"
train_dataset = load_dataset('billsum', split='train[0:1999]')
eval_dataset = load_dataset('billsum', split='test[0:199]')
generate_txt(train_txt_path, train_dataset)
generate_txt(eval_txt_path, eval_dataset)
happy_gen = HappyGeneration(model_type="GPTJ", model_name="EleutherAI/gpt-j-6b")
# happy_gen = HappyGeneration(model_type="LLAMA-2", model_name="meta-llama/Llama-2-7b-chat-hf")
train_args = GENTrainArgs(
fp16=True,
deepspeed="ZERO-2",
max_length = 256
)
happy_gen.train(train_txt_path, args=train_args, eval_filepath=eval_txt_path)
happy_gen.save("gptj/")
# happy_gen.save("llama/")
def generate_txt(txt_path, dataset):
with open(txt_path, 'w', newline='') as text_file:
for case in dataset:
text = case["summary"]
text_file.write(text + "\n")
if __name__ == "__main__":
main()Running the Script
To run the script use the command deepspeed instead of python3.
deepspeed train.py Results Llama-2
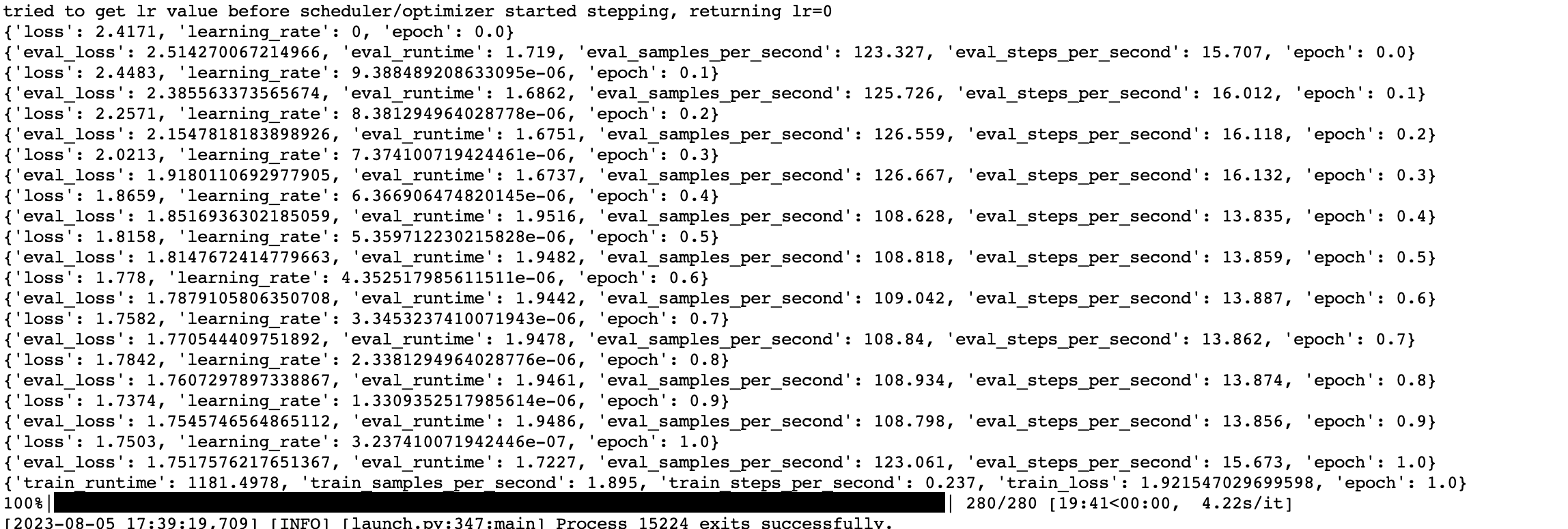
After the fine-tuning has been completed a model will be saved to the directory specified at the end of the script form the happy_gen.save() command.
As the script is running, you can run the command below in another terminal to monitor GPU usage.
watch nvidia-smi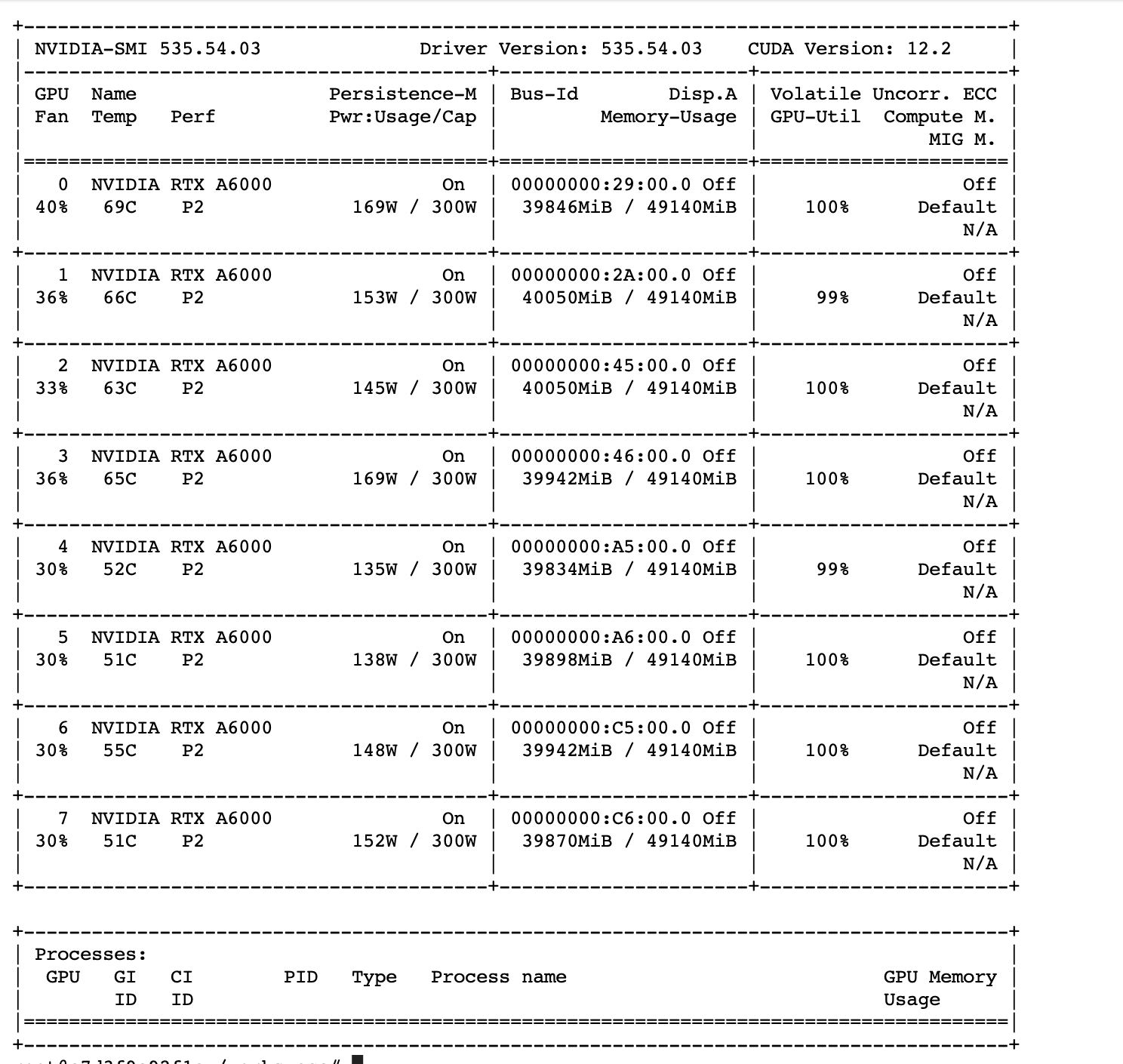
Part 5: WandB Tracking
First off create and account for WandB and then login though a terminal.
wandb loginYou can track your training run with the WandB platform with a simple change to the training script. Simply modify GENTrainArgs's report_to parameter to a tuple with a single argument called "wandb."
train_args = GENTrainArgs(
fp16=True,
deepspeed="ZERO-2",
max_length = 256,
report_to=('wandb'),
project_name = "happy-transformer",
run_name = "text-generation"
)
After rerunning the script again you'll be shown a link you can follow. You can explore various metrics from training, such as the eval loss and training loss.
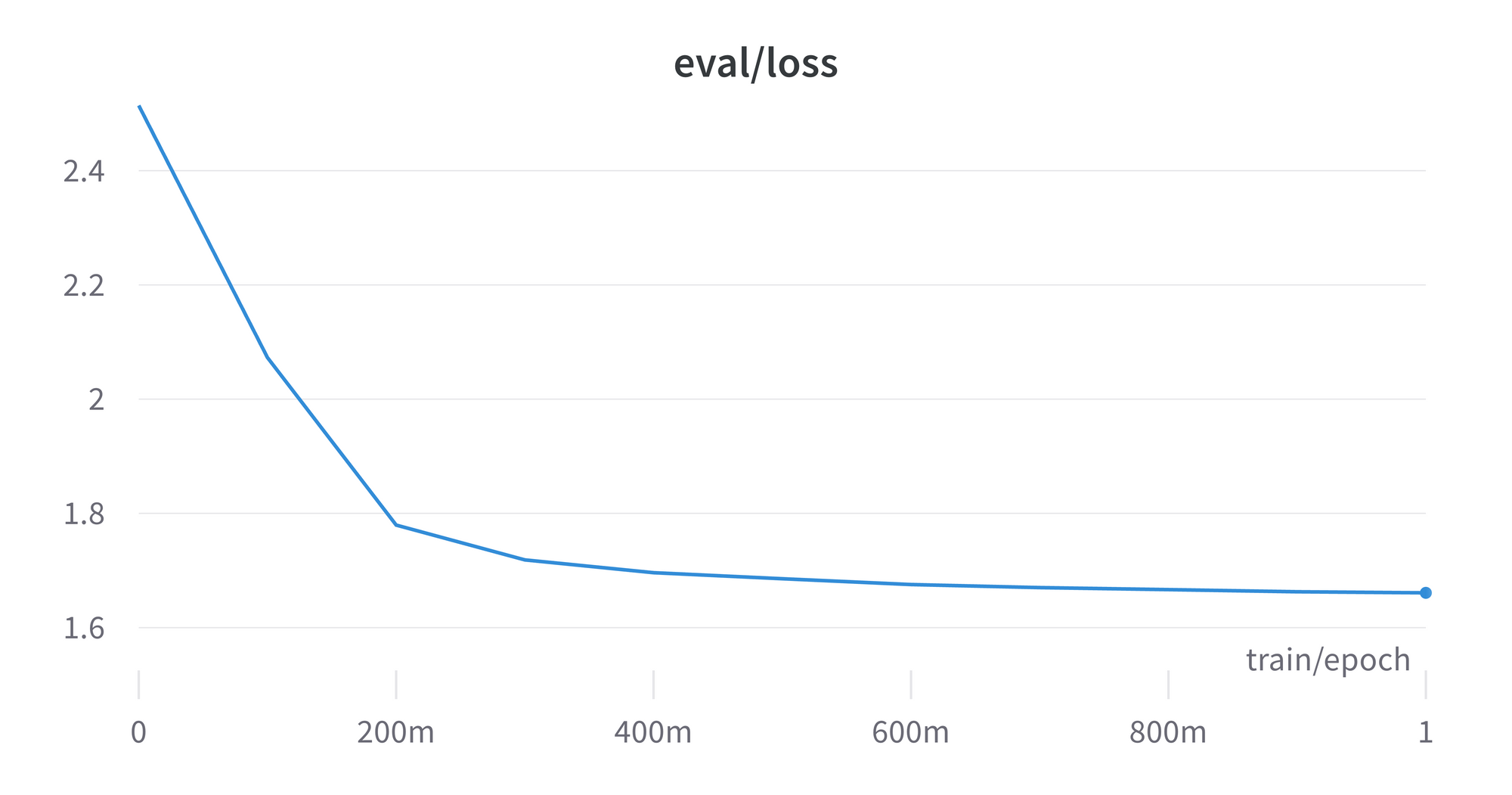
Part 6: Hyperparameters
I encourage you to try modifying other values within GENTrainArgs. For examle, you can try lowering the learning rate from its default value of 5e-5. You can find a list of values within Table 1.1 on this webpage. You can also find a definition for each learning parameter here.
train_args = GENTrainArgs(learning_rate=1e-5, num_train_epochs=2, fp16=True, deepspeed="ZERO-2", max_length = 256, report_to=('wandb'), project_name = "happy-transformer", run_name = "text-generation")
Part 7: Generate Text
You can create a Jupyter Notebook and run the code below to perform inference with the newly fine-tuned model. Provide the path you used for the happy_gen.save() at the bottom of the training script to the second position parameter for instantiating a HappyGeneration object.
from happytransformer import HappyGeneration, GENSettings
happy_gen = HappyGeneration("GPT-J", "gptj/")
# happy_gen = HappyGeneration("LLAMA-2", "llama/")
args = GENSettings(do_sample=True, top_k=50)
result = happy_gen.generate_text("We", args=args)
print(result.text)
Result: need more doctors, not just more training. Requires the Department of Health and Human Services (HHS) to establish at the beginning of each year the number of internships to train medical students as physicians in a specified geographical area.
As you can see, the model produced text that resembles a legal bill when given a generic prompt which suggests we've fine-tuned the model successfully..
Part 8: Push to Hugging Face's Model Hub
You can now push the model to Hugging Face's Mode Hub with one line of code. Replace "vennify" with your Hugging Face Username and "example" with the ID you would like to use.
happy_gen.push("vennify/example", private=True)Next Steps
Subscribe to Vennify's YouTube channel for upcoming content on NLP.




