Semantic Similarity With Sentence Transformers

In this tutorial we'll discuss how to compute the semantic similarity between text. Computing semantic similarity has many applications, including information retrial, search engines, data mining, and summarization. We'll use a Python package called SentenceTransformers that currently has over 7.8k GitHub stars and over 16.9 M downloads on PyPI. So by completing this tutorial, you'll learn how to leverage a top NLP package to perform a powerful NLP task.
Semantic Similarity
The process for computing semantic similarity between two texts with Sentence Transformers can be summarized in two simple steps. First, we convert the two texts into individual vector representations, which in the case of this tutorial will have 384 dimensions. Then, we used a metric like cosine similarity to determine the similarity between the two vectors we're comparing.
Vector Representations
Let's first discuss the concept of representing singular entities as vectors before discussing representing full sentences. In the figure below, we have five entities: a king, a queen, a prince, a princess, and a dog. The entities have similar meanings and are thus close together in the vector space. The king is closer to the queen and the prince than he is to the princess, and similarly, the queen is closer to the princess and the king than she is to the prince. The word dog shares little meaning with the other four, and thus it is far away from the other four.

This concept can be further applied to full sentences or even bodies of text which was done by the authors of SentenceTransformers in their paper "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks" in an efficient way. The model we'll be using can compute the vector representation for a body of text that contains up to 256 tokens, where each token is typically a word, subword, or special symbol. So this allows us to compute the semantic similarity between bodies of text that contain about 1-2 paragraphs.
Install
SentenceTransformers is available on PyPI and thus can be installed with pip.
pip install sentence-transformersImport
We need to import a class called SentenceTransformer which we'll use to instantiate the model. We also need to import a module called util, which contains a collection of helpful functions.
from sentence_transformers import SentenceTransformer, utilModel
We can use several different models, as shown on this webpage. Each has its own advantages and disadvantages in terms of size, speed, and performance compared to the other models. We'll use the same model from the official documentation for computing semantic similarity called "all-MiniLM-L6-v2." You may be interested in using the model "all-mpnet-base-v2" which has better performance but is five times slower than the one we'll use.
To instantiate a model, we need to provide the model name to the first positional parameter for the SentenceTransformer class.
model = SentenceTransformer('all-MiniLM-L6-v2')
Encode
Let's call our SentenceTransformer object's encode method and provide the text we want to encode. We'll repeat this two times with similar text. Calling this method will produce a vector representation of the meaning of the provided text.
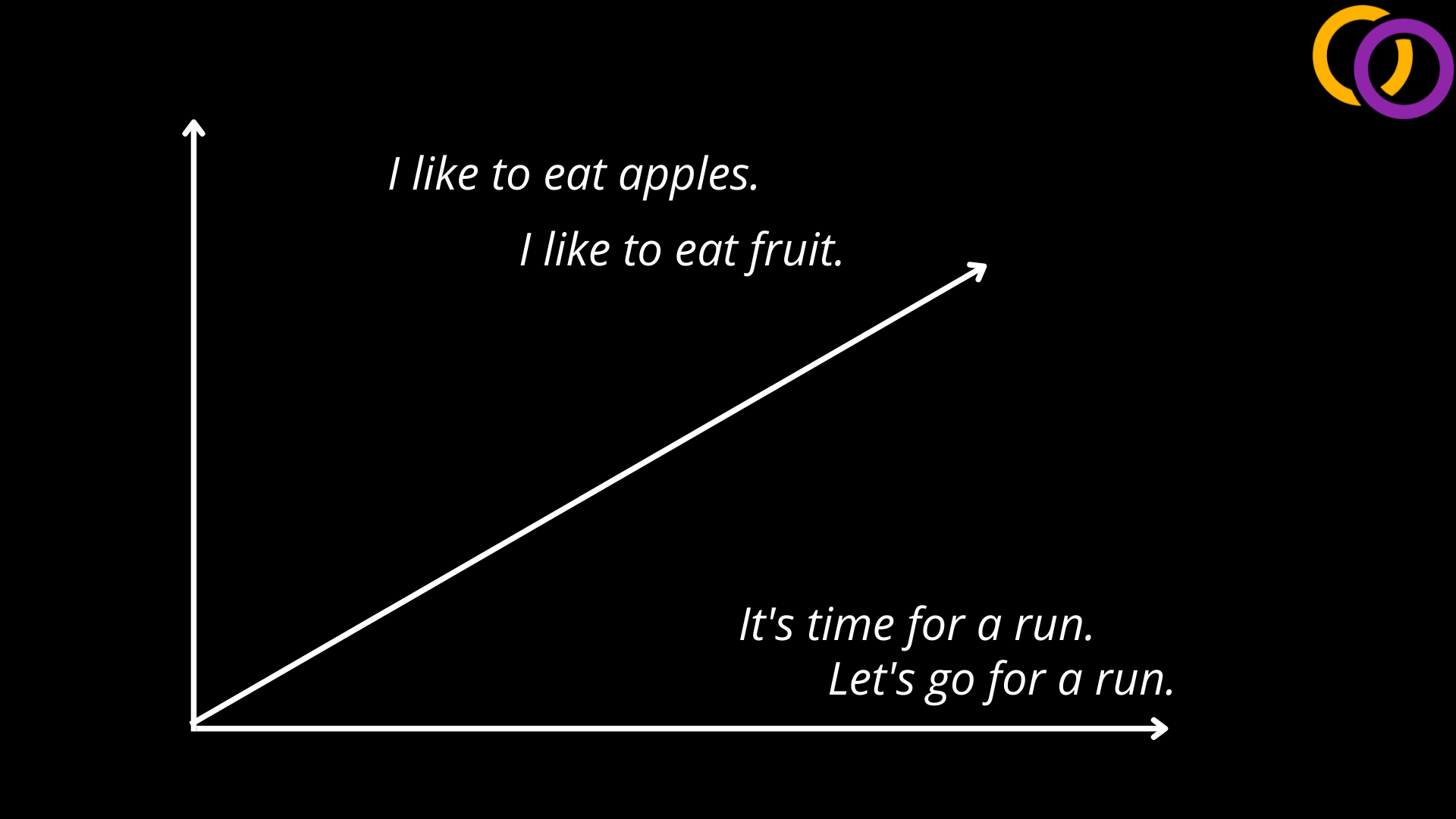
en_1 = model.encode("I like to eat apples")
en_2 = model.encode("I like to eat fruit")
print(type(en_1))
Output: <class 'numpy.ndarray'>
This produces a NumPy array. We can see its dimensions by accessing its shape attribute.
print(en_1.shape)Output: (384,)
As you can see the output is an array with 384 values, which matches the number of dimensions of the vector space.
Compute Cosine Similarity
Now that we have two vectors, we can compute the cosine similarity between them. This can be thought of as the angle between the two vectors. We can use a function within the util module to accomplish this called cos_sim() by passing the two vectors to the first two position parameters. We can expect the value to be between 0 and 1, where 1 indicates that the two texts are the same.
result = util.cos_sim(en_1, en_2)
print(result)
print(type(result))Output:
tensor([[0.7743]]) <class 'torch.Tensor'>
The output is a of type torch .Tensor which may be unfamiliar to some. We can convert it it into a float by calling ".item()".
result_float = result.item()
print(result_float)
print(type(result_float))Output:
0.774281919002533
<class 'float'>
Compute Dot Product
We can also compute the dot product instead of the cosine similarity. This article will not discuss the technical differences between these two – that may come in another article, so be sure to subscribe to my newsletter. But, we will show how to compute it. To compute the dot product, we must call a function called dot_score() from the util module and provide the two vectors as we did before for the cos_sim() function.
result = util.dot_score(en_1, en_2)
print(result.item())
Output:
0.836174726486206
Multiple Text Inputs at Once
Data
Our SentenceTransformer object allows us to encode multiple sentence at once by passing a list of strings instead of a single string as we did before.
sents_1 = ['Go plant an apple tree',
'I like to run',
'Can you please pass the pepper']
sents_2 = ['Go plant a pear tree',
'I like to code',
'I want to buy new socks']Encoding
We can now called SentenceTransformer's encode method once again.
em_1 = model.encode(sents_1)
em_2 = model.encode(sents_2)Cosine Similarity
Let's now compute the cosine similarity between em_1 and em_2. We can accomplish this by calling cos_sim() once again.
cosine_scores = util.cos_sim(em_1, em_2)
print(type(cosine_scores))
print(cosine_scores)
Output: <class 'torch.Tensor'>
tensor([[0.6896, 0.1329, 0.0814],
[0.1780, 0.4320, 0.1514],
[0.1659, 0.1660, 0.0806]])
The output is a matrix where each vector from em_1 was compared to each vector from em_2.
Display Results
Let's display the results or comparing the the ith index of the em_1 to the ith index of em_2.
for i in range(len(sents_1)):
result = cosine_scores[i][i].item()
print("sent_1: ", sents_1[i])
print("sent_2: ", sents_2[i])
print("result: ", result)
print("----------------------------------"))
Output:
sent_1: Go plant an apple tree
sent_2: Go plant a pear tree
result: 0.6896440982818604
----------------------------------
sent_1: I like to run
sent_2: I like to code
result: 0.43197232484817505
----------------------------------
sent_1: Can you please pass the pepper
sent_2: I want to buy new socks
result: 0.08064968138933182
----------------------------------
Conclusion
We just covered how to use SentenceTransformer to compute the semantic similarity between two sentences. We've just scratched the surface of this topic, and I plan on creating more content on it in the future. In the meantime, be sure to subscribe to Vennify.ai's YouTube channel and to our newsletter. You may also be interested in checking out our previous article that covers how to train a text classification Transformer model and evaluate it using Hugging Face's new Evaluate library.
Here's the Google Colab for this tutorial




