GPT-Neo With Hugging Face's Transformers API

A grassroots movement called EleutherAI has been working hard on democratizing state-of-the-art natural language processing (NLP) models, and one of their latest models, called GPT-Neo, is no exception. GPT-Neo is a fully open-source version of Open AI's GPT-3 model, which is only available through an exclusive API. EleutherAI has published the weights for GPT-Neo on Hugging Face’s model Hub and thus has made the model accessible through Hugging Face’s Transformers library and through their API.
The largest GPT-Neo model has 2.7 billion parameters and is 9.94 GB in size. Thus, it requires significant hardware to run. For example, I tried running the model on Google Colab with a high memory instance but experienced a crash. So, I suggest you consider Hugging Face’s inference API if you are looking for a simple and clean implementation.
By using their Hugging Face's API, you can simply make a request to their servers to generate text with GPT-Neo. This way, you do not have to worry about your system's hardware and can get straight to generating text using a state-of-the-art NLP model. So, whether you're just implementing the model for fun or are implementing it to serve 100s of requests per hour -- Hugging Face's API has you covered.
Implementation
First off, we need to create a Hugging Face account. Head over to this URL to complete the sign-up process. Then head over to this URL to see the web page for the 2.7 billion parameter version of GPT-Neo. Now, click on the “Deploy” button as shown below and select “Accelerated Inference.”
This will then generate code that you can use to deploy the model.
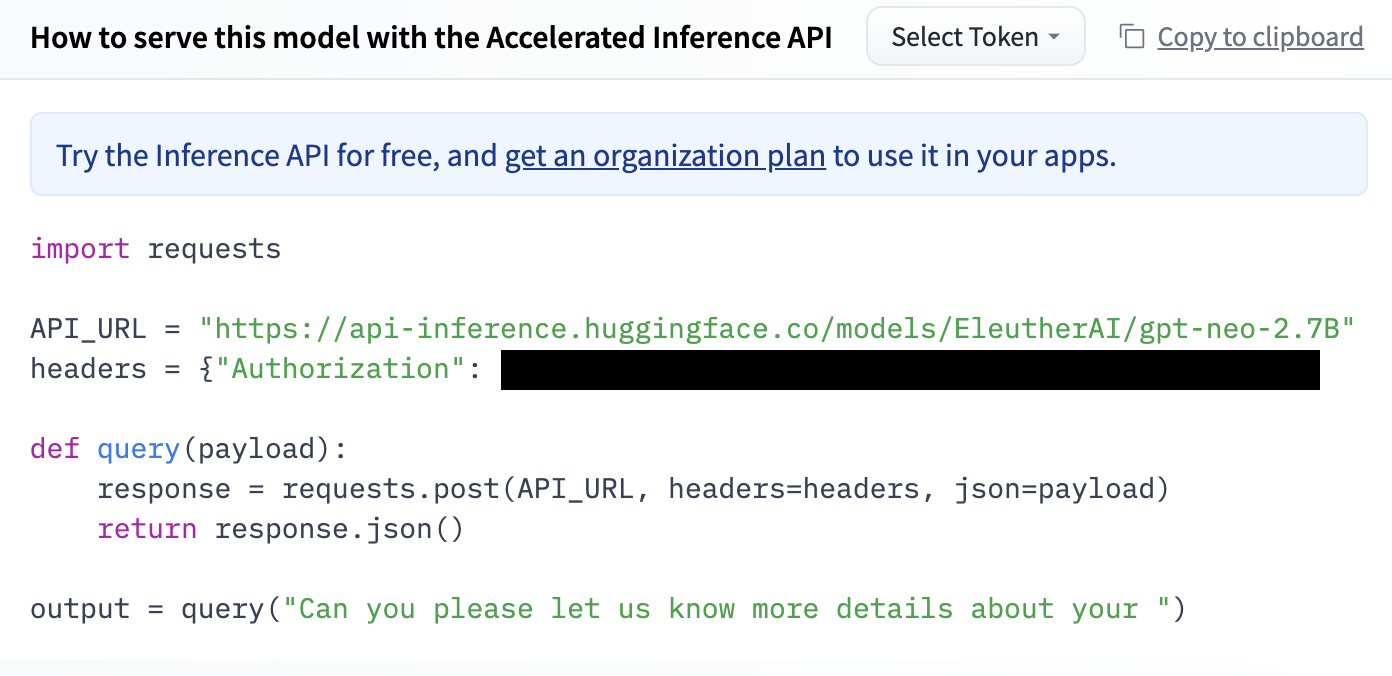
Be sure to pip install the requests library within your environment with the following line of code.
pip install requestsBelow is the generated code, except I changed the query. I also added comments to add clarity to the code.
# the package we'll use to send an
# HTTP request to Hugging Face's API import requests
import requests
# A URL to indicate which model we'll use.
#If you visit it, the page displays information on the model.
API_URL = "https://api-inference.huggingface.co/models/EleutherAI/gpt-neo-2.7B"
# A dictionary that contains our private key.
# Be sure change this to include your own key.
headers = {"Authorization": "PRIVATE"}
# A method that we'll call to run the model
def query(payload):
# Makes a request to Hugging Face's API
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
output = query("I have a great idea!")
print(output)
Result:[{'generated_text': ' making the UK an economically and socially prosperous nation; we must work towards the development and implementation of sustainable energy systems; we must work towards ensuring that we use as much renewable energy as possible, and that we are an attractive place to'}]
The output is a list of dictionaries that contain a single key called "generated_text." We are only generating a single output, so we can isolate the text from the top result as shown below.
print(output[0]["generated_text"])Result: making the UK an economically and socially prosperous nation; we must work towards the development and implementation of sustainable energy systems...
Custom Generation
We're able to modify the text generation algorithm that's used to produce text. By default, an algorithm called "greedy" is used, which simply selects the token with the highest probability one at a time. Now, we can allow the model to select tokens with a lower probability by adjusting the parameters. This typically results in text that is "more creative" and less prone to repetition.
Here's a link to the various setting you can adjust. In this article, we'll use an algorithm called "top-k sampling" with a k of 10. This means the model will consider the top 10 tokens with the highest probability, and amongst those 10 tokens will be more likely to select the tokens with a higher probability.
To accomplish this functionality, we must adjust the values within our payload variable. Right now, we're just providing the prompt in the form of a string. But, if we wish to use additional parameters, we must convert our payload variable to a JSON string using the proper variables. Below is updated code that shows this process while setting the "top-k" parameter to 20.
import json
import requests
headers = {"Authorization": "PRIVATE"}
API_URL = "https://api-inference.huggingface.co/models/EleutherAI/gpt-neo-2.7B"
def query(payload):
data = json.dumps(payload)
response = requests.request("POST", API_URL, headers=headers, data=data)
return response.json()
output = query({"inputs": "Please pass the", "top_k": 20})
print(output)
print(output[0]["generated_text"])Result: love onto those with allergies to make certain not ALL that is out this summer goes up against our noses
GPT-J
Some of you may be wondering if it's possible to do the same with EleutherAI newest model called GPT-J. This model has 6 billion parameters and is also available on Hugging Face's Model Hub. However, the following error is currently being returned from the request.
{'error': 'The model EleutherAI/gpt-j-6B is too large to be loaded automatically.'}
Perhaps a premium plan is required to run the model.
Conclusion
And that's it, I hope you learned a lot! Below are a couple of related resources you may be interested in to extend your learning. Be sure to subscribe to my mailing list and also to my YouTube channel.
Train GPT-Neo
Here's a related article I published that discusses how to run and train GPT-Neo on your own device using my very own library called Happy Transformer .
Course
If you want to learn how to create a web app to display GPT-Neo, and how to fine-tune the smallest 125M model, then I suggest you check out this course I created. I attached a coupon to the link.




