Are Zero-Shot Text Classification Transformer Models the Key to Better Chatbots?

One of the most cumbersome tasks for many natural language processing (NLP) projects is collecting and labelling training data. But, there's a potential solution to this problem when it comes to intent classification for chatbots, and that is using zero-shot text classification Transformer models. If successful, this method would reduce the complexity required for developing chatbots while potentially improving their performance. I encourage you to expand upon these ideas and possibly integrate them into your chatbot systems.
Intent classification is a fundamental tasks that chatbots perform. Intent classification is the act of determining which action the user wishes to perform. For example, say you ask a chatbot, "Please play U2's newest song," then the bot must determine that the user wishes to "play a song." From there, the model would typically use entity recognition to determine which song to play. This article proposes a possible way to leverage new technologies to perform intent classification without any training data.
Zero-Shot Text Classification
Zero-shot text classification Transformer models were proposed in 2019 in the paper "Benchmarking Zero-shot Text Classification: Datasets, Evaluation and Entailment Approach" [1]. The input to the model is phrased as an entailment problem for each label. So, given the text "I would like to buy an apple" and the label "food" the premise would be the text and the hypothesis would be something similar to "This text is about food." Then, the model determines if the hypothesis entails, or does not entail the premise. With this technology, NLP practitioners can train their models on a single text entailment dataset and then use that model to perform text classification for any arbitrary label.

We'll use the second most downloaded zero-shot text classification model on Hugging Face's model distribution network, which was created by Facebook AI. It was released under an MIT license, which is a permissive licence you can read more about here.
Architecture
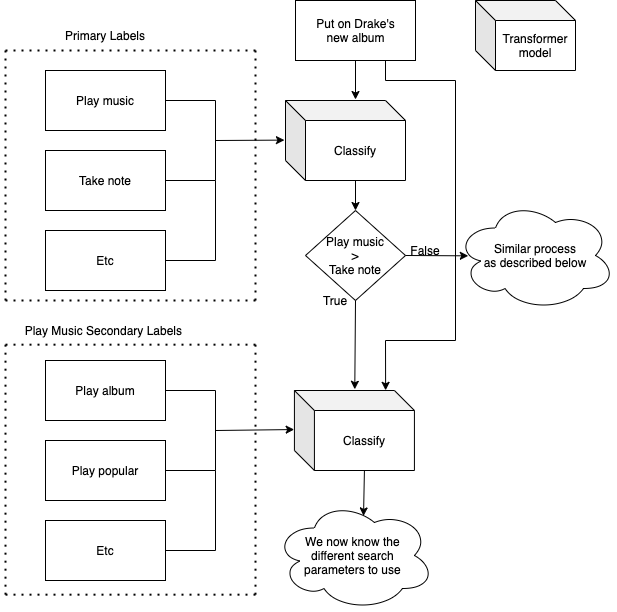
This article proposes a tree-based intent classification system that leverages zero-shot text classification models. Some intents may be classified together, and thus, I believe it is better to first determine the category of intent and then determine the specific action(s) to perform. For example, a category may be "play music," and then intents for the category may be "play artist" or "play album."
Without applying a zero-shot model, using a similar tree-based system may be out of reach for two main reasons. First, you would likely need a single model to classify the category and then a model for each of the categories. So, if you're dealing with a system with a large variety of possible actions, this could add up to be a lot of models. And then, due to an increased number of models and categories, more training would be required. So, by using this proposed system, only a single model is required for this entire tree-based classification system.
Model Creation
Currently, Hugging Face's Transformers library is the go-to way to implement zero-shot text classification Transformer models. And thus, we can download the package from PyPI with the following line of code.
pip install transformers
Hugging Face created a function called "pipeline" that abstracts the complexities typically involved with using Transformer models for inference. Let's import it.
from transformers import pipelineWe need to provide the task we wish to perform and the model name to the pipeline class. Then, it will output an object we can use to begin classifying text. The task id is "zero-shot-classification" and the model's name is "facebook/bart-large-mnli".
task = "zero-shot-classification"
model = "facebook/bart-large-mnli"
classifier = pipeline(task, model)Primary Intent Classification
Let's define an arbitrary list of labels for our model to classify text into. For this example, I'll add labels for common tasks a virtual phone assistant will perform.
primary_labels = ["take note", "play music", "search internet ", "send email", "create reminder"]
We can now classify text into one of these labels. First off, let's define text that's related to one of these labels. We'll use an example that falls under the "play music" category.
input_text = "Put on Drake's new album"To produce a prediction, we can provide the text and the labels to our classier as shown below.
classifier_output = classifier(input_text, primary_labels)
We can now print the results.
print(classifier_output["labels"])
print(classifier_output["scores"])Result:
['play music', 'take note', 'create reminder', 'search internet ', 'send email']
[0.8064008355140686, 0.1329479217529297, 0.04738568142056465, 0.010709572583436966, 0.0025559617206454277]
Both the labels and the scores are sorted by highest score. So here we see that "play music" was the top result with a score of 80.64% which makes sense.
Secondary Intent Classification
For each of the primary labels, we must create a list of secondary labels to further refine what the user intends to do. Continuing the example above, since the primary label is "play music" below is a list of potential actions.
secondary_labels = ["play artist", "play song", "play album", "play popular", "play new", "play old"]As before, we can use the zero-shot text classification model to determine the intended action. We'll provide the original text and the secondary labels to model.
secondary_classifier_output = classifier(input_text, secondary_labels)
print(secondary_classifier_output["labels"])
print(secondary_classifier_output["scores"])Result:
['play album', 'play artist', 'play new', 'play popular', 'play song', 'play old']
[0.2994290888309479, 0.23053139448165894, 0.2097683995962143, 0.1356963962316513, 0.12262289971113205, 0.0019517639884725213]
And there we go! We just determine which actions to perform. We see that "play artist," "play album" and "play new" all scored high. So now we can use entity recognition to detect an artist within the text and then query for the artist's newest album.
Conclusion
In this article I proposed a way to leverage a zero-shot text classification model to eliminate the need for training data for intent recognition. I also discussed how this method can be used to create a tree-like search algorithm to refine the exact action the user wishes to perform. I hope this article inspires you to create more powerful chatbots!
Please email eric@vennify.ca if you successfully implement this proposed method for a project. I would love to hear about it.
References
[1] W. Yin, J. Hay, D. Roth, Benchmarking Zero-shot Text Classification: Datasets, Evaluation and Entailment Approach (2019), EMNLP 2019
[2] A.Williams, N. Nangia, S. Bowman, A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference (2018), Association for Computational Linguistics
Resources:
Similar Article
If you enjoyed this article, then you may also enjoy the article below that covers an original research project by me that involves zero-shot text classification Transformer models.
Title: How to Label Text Classification Training Data -- With AI
Summary: Use a zero-shot text classification model to label training data. Then, use the labelled training data to fine-tune a small supervised model that can be used in production more easily.




